그래프에서 하나의 노드로부터 각 노드까지의 최단 거리를 구하기 위한 알고리즘으로,
코딩 테스트의 경로 탐색 문제를 해결하기 위해 기본적으로 알아야 한다.
다익스트라와 달리 모든 노드 쌍에 관한 최단 거리를 구하는 '플로이드-워셜 알고리즘'이 있다.
(다익스트라를 각 노드에 대해 구하면 동일하게 모든 쌍에 관한 최단 거리를 구할 수 있다.)
동작
dist[i] = min( dist[i], dist[j] + wieght[j][i] )
(i노드까지의 최단거리) = (현재 i 노드까지의 최단거리), (이전 노드 j까지의 최단거리 + j 에서 i까지 거리)
두 값중 작은 값을 취하면 된다. 위 공식을 시작 노드로부터 점진적으로 진행시키면 된다.
BFS와 같이 queue를 이용하여 다음 노드로 진행 시키는데, 우선 순위 큐(힙)을 사용하면
업데이트 횟수가 줄어들어 더 빠르게 진행할 수 있다. (여기서도 우선 순위 큐로 설명한다.)
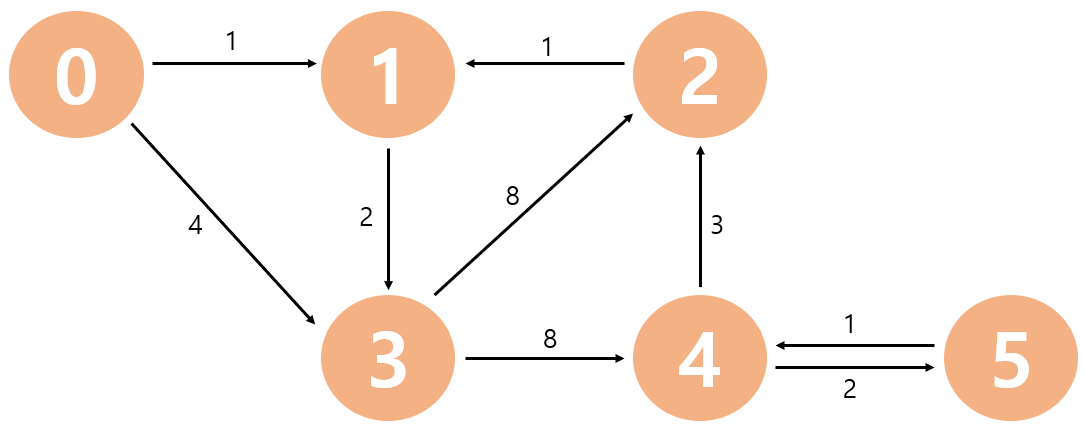
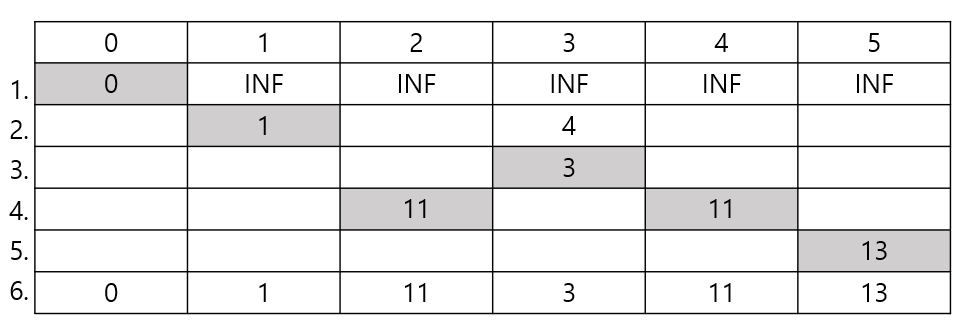
먼저 최단 거리를 저장한 배열을 선언하고 시작 노드(0번)에 거리(시작이므로 0)를 표시한 뒤,
나머지 노드에 INF(무한한값, 보통 -1로 둔다.)으로 채워 넣고, queue에 시작 노드를 넣는다.
1. queue에서 데이터를 꺼내어(0번) 연결된 모든 노드(1, 3번)의 거리를 계산하고 기록한 뒤,
기록된 거리값으로 queue에 삽입한다.
2. queue에서 데이터를 꺼내어(최소힙이므로 1번) 연결된 모드 노드(3번)의 거리를 계산하여 더 작으므로
업데이트 한다. 업데이트 되었으므로 다시 queue에 삽입한다.
3. queue에서 데이터를 꺼내고(3번) 연결된 모든 노드(2, 4번)의 거리 계산 후 기록한 뒤, queue에 삽입한다.
구현에 따라 다르지만, 현재 queue에 거리4로 먼저 넣은 3번 노드가 있지만 거리3으로 구한 것이 최단이므로,
무시된다. 최소힙으로 구현하는 이점이다.
4. queue에서 데이터를 꺼내어(2번) 연결된 모든 노드(1번)의 거리를 계산하지만 이미 1번에 더 작은 값이 있으므로,
무시된다. 또 데이터를 꺼내어(4번) 연결된 모든 노드(5번)에 대해 계산하여 갱신 시킨다. 그 후 queue에 넣는다.
5. queue에서 데이터를 꺼내어(5번) 연결된 모든 노드(4번)에 대해 계산하지만 이미 작은 값이 있어 무시된다.
queue에 더이상 데이터가 없으므로 알고리즘을 종료한다.
6. 시작 노드(0번)으로부터 각 노드까지의 최단 거리가 다 구해졌다.
코드
public class graph {
// 최소힙에 넣기 위해 정의한 (노드번호, 거리)쌍의 클래스
private class _pair implements Comparable<_pair> {
public int dst;
public int weight;
public _pair(int d, int w) {
this.dst = d;
this.weight = w;
}
// 비교를 위해 Override
@Override
public int compareTo(_pair target) {
return this.weight <= target.weight ? -1 : 1;
}
}
private ArrayList<_pair>[] adjList; // 인접 리스트
private PriorityQueue<_pair> queue; // 우선 순위 큐
private int[] shortestDist; // 최단 거리 배열
public graph(int n) {
adjList = new ArrayList[n];
shortestDist = new int[n];
Arrays.fill(shortestDist, -1);
for (int i = 0; i < n; i++) {
adjList[i] = new ArrayList();
}
queue = new PriorityQueue<>();
}
// 간선 추가
public void addEdge(int src, int dst, int w) {
this.adjList[src].add(new _pair(dst, w));
}
// 다익스트라
public void dijkstra(int start) {
// 시작 노드 삽입, 거리 행렬 기록
queue.offer(new _pair(start, 0));
shortestDist[start] = 0;
// 큐에 데이터가 없을 때까지
while (!queue.isEmpty()) {
_pair p = queue.poll();
for (_pair adj : adjList[p.dst]) {
int dist = adj.weight + p.weight;
// 계산된 거리가 기록되어있는 거리보다 작거나
// INF값( -1 )일 경우
if (dist < shortestDist[adj.dst] || shortestDist[adj.dst] == -1) {
shortestDist[adj.dst] = dist;
queue.offer(new _pair(adj.dst, dist));
}
}
}
}
// 최단 거리 배열 출력
public void printDist() {
for (int i : shortestDist) {
System.out.print(i + " ");
}
System.out.println();
}
}public class Main {
public static void main(String[] args) {
graph g = new graph(6);
g.addEdge(0, 1, 1);
g.addEdge(0, 3, 4);
g.addEdge(1, 3, 2);
g.addEdge(2, 1, 1);
g.addEdge(3, 2, 8);
g.addEdge(3, 4, 8);
g.addEdge(4, 2, 3);
g.addEdge(4, 5, 2);
g.addEdge(5, 4, 1);
g.dijkstra(0);
g.printDist();
}
}'프로그래밍 > Java' 카테고리의 다른 글
| 너비 우선 탐색(BFS) (0) | 2019.10.21 |
|---|---|
| 깊이 우선 탐색 (DFS), 인접 행렬, 인접 리스트 (0) | 2019.10.18 |
| [Android] 사설 SSL 인증서를 이용한 https 통신 (4) | 2018.05.30 |
| [JAVA] NFC 제어 (2) | 2017.10.15 |
| [Android] HCE를 이용한 NFC 통신 (8) | 2017.10.15 |