방문자 패턴은 연산(행동)을 적용할 클래스를 변경하지 않고도 새로운 연산을 정의할 수 있게 하는 패턴이다.
방문자 패턴은 단일 클래스로만 구성 되어 있을때도 유용하지만, 이미 수많은 클래스가 "군"(많은 결합)을
이루고 있어서, 새로운 기능 추가시 많은 비용( 많은 수정 )이 들어갈때 매우 유용하게 사용할 수 있다.
(수정하는 양이 많아지면, qa 대상도 곱으로 늘어난다)
예를 들어 현재 라이브 서비스중인 게임회사에 새로 입사했다.
프로그래머가 1명뿐이던 영세 회사인데, 이전 프로그래머가 그만두면서 들어와서 legacy 코드를 물어볼 사람도 없다.
(실제 상황이라면, 뤈)
현재 웹서버 기반(HTTP)으로 게임을 만들었으나, 답답한 지연성 때문에 좀더 compact하게
깡 TCP로 만들기로 하여, 일단 간단히 TCP Socket으로 송수신 가능한 기능을 만들었다.
class TCPClient
{
public:
//@brief : socket 초기화 및 서버 연결등의 처리
void init(void) noexcept;
//@brief : 별도의 스레드에서 로그아웃, 종료, 서버 응답 없음 등의 이유로 게임이 종료되어야 할때까지 실행됨
void run(void) noexcept;
//@brief : 송/수신 관련 인터페이스.
//{@
void send(void) noexcept;
void receive(void) noexcept;
//@}
};
이제 기존에 HTTP로 요청하던 부분들을 다음과 같이 변경할 것이다.
class Player
{
public:
void func(void) noexcept
{
// 플레이어 관련 동기화 데이터 전송
//httpClient->requect();
tcpClient->send();
}
};
근데 얼마 안가서 또 이번에는 TCP의 "연결지향성"이 여전히 느리다 판단하고, UDP로 변경하자고 한다....
이럴때마다, 코드를 다 엎는 거는 힘들고(심지어 라이브 서비스중) 지친다. 이럴때 "방문자 패턴"을 적용해보자.
class NetworkingVisitor
{
public:
virtual void visit(Player* player) noexcept = 0;
};
class TCPVisitor : public NetworkingVisitor
{
public:
virtual void visit(Player* player) noexcept
{
// tcp용 패킷 만들기
_tcpClient->send();
}
};
class HTTPVisitor : public NetworkingVisitor
{
public:
virtual void visit(Player* player) noexcept
{
// http용 패킷 만들기
_httpClient->request();
}
};
networking 기능을 확장시킬 NetworkingVisitor를 interface로 만들고, 프로토콜별로 기능을 수행할 TCPVisitor와
HTTPVisitor를 추가하였다.
이제 Player class는 visitor를 방문하기만 하면 해당 기능을 사용할 수 있다!
#define Networking_Method new TCPVisitor()
//#define Networking_Method new HTTPVisitor();
class Player : GameObject
{
public:
void func(void) noexcept
{
// 플레이어 관련 동기화 데이터 전송
//httpClient->requect();
//tcpClient->send();
NetworkingVisitor* visitor = Networking_Method;
visitor->visit(this);
}
};
이렇게 Player코드에서 아예 네트워킹 관련 코드는 빠지게 되고, Player class와
TCPClient class(혹은 HTTPClient)와의 결합도 사라졌다. (c++이니까 define으로 switch 쉽게 해둔 것은 덤.)
서두에서 말했듯 수많은 클래스에 걸쳐서 비슷한 연산(기능)을 추가할때 기존 구조를 확장할 수 있어서
유용하게 사용할 수 있다.
또한, 위 예제 처럼 visitor만 교체하면 새로운 기능을 할 수 있으므로, 일종의 "전략 패턴"으로도 볼 수 있다.
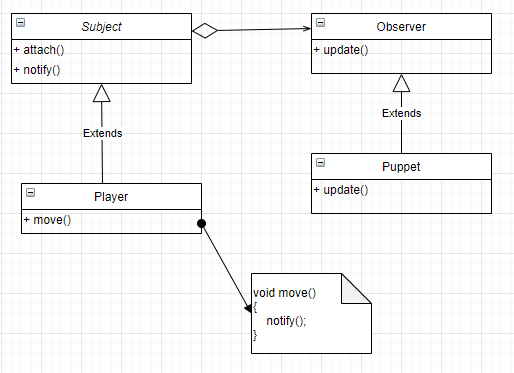
옵저버 패턴은 어떤 객체의 상태가 변할 때 함께 동작하고 싶은 즉, 그 객체에 의존성을 가진
객체들이 자동으로 감지하고 갱신될 수 있게 하는 패턴이다.
1. 의존 관계 분리
보통 이러한 패턴들을 접해보지 않은 분들( 혹은 패턴을 접했어도, 그 중요성(존재 이유)을 잘 모르는 분들)은
어떤 객체의 변화에 따라 함께 변화해야할때 다음과 같이 작성한다.
class Player
{
public:
void move(void) noexcept
{
// 소유하고 있는 인형을 움직여 준다.
_puppet.move();
}
private:
Puppet _puppet;
};
void main()
{
Player player;
player.move();
}
player의 움직임에 따라 player가 보유 및 소환한 퍼펫들이 있다면, 퍼펫들의 move() 메소드를 같이 호출한다.
player가 이러한 아주 간단한 클래스 라면 문제가 없지만, 점점 복자해지고 수많은 필드를 가지게 되면
문제가 발생한다.
void move(void) noexcept
{
// 소유하고 있는 인형을 움직여 준다.
_puppet.move();
// 카메라 위치를 적절히 바꾼다.
_camera.move();
// 캐릭터를 중심으로 표시하는 미니맵 정보들
_minimap.updateActors();
// 캐릭터를 따라다니는 status 정보
_status.updateInfos();
// ... 수많은 의존 객체들 ...
}
좀 극단적인 예 이지만, 이러한 코드 작성이 있을법한 얘기이다. (게임 뿐만 아니라, 응용 프로그램, 웹 등에서도....)
요러한 의존 관계를 옵저버 패턴을 통해 분리할 수 있다.
2. 옵저버 패턴 구현
객체의 상태변화가 여러개 라면 옵저버들은 어떤건 받고 어떤건 받고 싶지 않을 때가 있다. 그래서 옵저버들의
우리가 코딩할때 stack overflow나 블로그를 뒤져가면서 관련 코드를 찾고, 그대로 따라서 타이핑 해도 되지만, 바로 복사해서 쓰듯(ㅋㅋ), 객체의 생성때마다 매번 재생성 하고 관련 파라미터를 세팅해주는 것이 아니라, 이미 세팅된 애를 복사해서 사용할때 유용하다.
이미 세팅된 애를 복사해서 쓰기 때문에, 객체 생성과정이 매우 복잡 or 비용이 크다면 ( DB 에서 참조, File I/O 등 ) 해당 비용을 줄일 수 있다!
또, 팩토리 패턴처럼 별도의 creator를 만들지 않아도 되니 서브클래스 숫자가 줄어드는 장점도 있다.
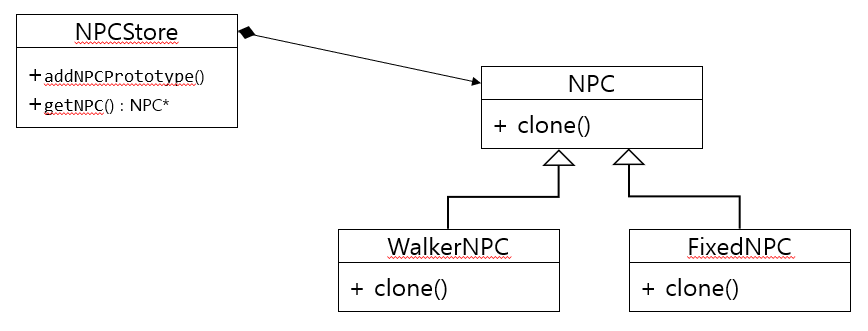
여러분은 npc를 만들고 배치 시키는 기능을 지원하기 위한 사전 작업을 하기로 했다.
오픈월드 게임을 해본 분들은 아시겠지만, 메쉬만 다르고 똑같은 액션 똑같은 행동들을 하는 npc들이 즐비해있다. 실제 게임을 만들때 그러한 npc들을 여기저기 배치해둘 것이다. (안그럼 밋밋해보이고, 모든 npc를 개성있게 만들기에는 시간이 부족하며 가성비가 안나온다...)
clone 메소드를 override하여 각 종류의 npc 인스턴스를 만든뒤 대입 연산자를 통해 copy 한다.
(인스턴스의 copy를 shallow copy로 할지 deep copy로 할지는 요구사항에 따라 결정하여 구현한다.)
이제 npc들의 '원형'들을 만들어 store에 등록해두자!
(예제라 코드로 하지만, 실제 엔진이라면 툴 차원에서 지원할 것이다.)
NPCStore* store = NPCStore::This();
//1) speed가 빠른 행인 npc
NPC* npc = new WalkerNPC(200);
store->addNPCPrototype("Fast_NPC", npc);
//2) speed가 느린 행인 npc
npc = new WalkerNPC(10);
store->addNPCPrototype("Slow_NPC", npc);
//3) hp가 높은 고정 npc
npc = new FixedNPC(100000);
store->addNPCPrototype("High_Hp_NPC", npc);
//4) hp가 낮은 고정 npc
npc = new FixedNPC(20);
store->addNPCPrototype("Low_Hp_NPC", npc);
이처럼 store 같은 'manager'가 있으면 같은 class의 인스턴스라도 다른 state( WalkerNPC의 speed, FixedNPC의 hp)를
가지는 새로운 원형으로 등록시키는게 가능하다!
NPC* clonedNPC;
//1) speed가 느린 행인 npc
clonedNPC = store->getNPC("Slow_NPC");
clonedNPC->info();
//2) hp가 높은 고정 npc
clonedNPC = store->getNPC("High_Hp_NPC");
clonedNPC->info();
스토어로부터 새로운 npc 인스턴스를 얻었으니 배치할 수 있다!
이처럼 유용한 패턴이지만 역시 단점도 있다.
바로 clone() 메소드이다.
clone() 메소드를 반드시 구현해야 하는데, 다음과 같은 3가지 사항에서 clone() 메소드 구현이 어려울 수 있다.
1. 이미 존재하는 class를 prototype으로 만드려 할때 어려울 수 있다.
2. 언어적으로 '복사'를 지원하지 않는다.
3. 환형참조가 있는 object
또한, concrete class에서만 아주 특별하게 쓰는 field( member variable )가 있고, 이 field를 외부에서
참조해야 하는경우 결국 down cast가 발생한다.
(근데 이건 subclass를 은닉시키는 모든 상황에서 발생가능한 것이므로, 그러한 상황이 나오지 않게
디자인 패턴을 따로 공부하지는 않았고(학부때 관련 전공필수 과목이 없었다...), 현업에서 개발을 하다가
접하게 되어 조금씩 생각날때 정리를 해보려한다. 들어가기 전에 기억해야할 것은
책에 나온 패턴들을 곧이곧대로 사용하려 하면 안된다. "만능, 치트키" 같은 물건이 아니며, 맹목적으로
그러한 설계(상속, 연관등의 구조)를 따를 필요는 없다. 개념을 이해하고 유연하게 바꾸어 사용하자.
어차피 곧이 곧대로 적용할 수 있을 정도로 프로덕트 코드들이 단순하지 않다.
(늘 문제는 생각하지 못한곳에서 발생하는 프로그래밍의 오묘한 세계...)
개요
먼저는 Manager 계열의 Class 설계시 아주 빈번하게 사용되고 있는 "생성" 패턴인 Factory에대해 알아보려 한다.
그중에 가장 단순한 형태인 Simple Factory가 이번 주제인데, 사실 Simple Factory라고 부르지만
실제 "패턴"으로 치지는 않는 아주 단순한 구조이다.
왜 사용할까?
구상 클래스를 중심으로 작성되는 코드는 결합도가 높아서 나중에 수정사항들이 생기면 "빈번한" 수정을 가해야한다.
그래서 결합도를 줄여 유지보수성을 높이기 위해 자주 사용된다.
예를들어 다음과 같은 코드가 있다.
class Monster
{
public:
virtual void attack(void) = 0;
};
class MushroomMonster : public Monster
{
public:
virtual void attack(void)
{
std::cout << "Mushroom attacked!" << std::endl;
}
};
class SnailMonster : public Monster
{
public:
virtual void attack(void)
{
std::cout << "Snail attacked!" << std::endl;
}
};
int main(void)
{
Monster* monster1 = new MushroomMonster();
Monster* monster2 = new SnailMonster();
monster1->attack();
monster2->attack();
/*
...
*/
Monster* monster3 = new MushroomMonster();
Monster* monster4 = new SnailMonster();
monster1->attack();
monster2->attack();
return 0;
}
Monster class를 상속받는 버섯몬스터 클래스와 달팽이몬스터 클래스가 있고, 단순하게 new를 해서
부모 class의 pointer로 받아서 객체를 핸들링 하는 코드가 있다. 이때 기획이 바뀌어 몬스터들에게
"체력 게이지"라는 스펙을 넣게 되었다 하자. 모든 몬스터는 반드시 hp를 가져야 하므로,
setter 메소드가 아닌, constructor에 강제하는것이 좋으므로 다음과 같이 변경했다.
class MushroomMonster : public Monster
{
public:
MushroomMonster(int hp)
: _hp(hp)
{
}
virtual void attack(void)
{
std::cout << "Mushroom attacked!" << std::endl;
}
private:
int _hp;
};
class SnailMonster : public Monster
{
public:
SnailMonster(int hp)
: _hp(hp)
{
}
virtual void attack(void)
{
std::cout << "Snail attacked!" << std::endl;
}
private:
int _hp;
};
# _hp를 Monster에 추가해줄 수 있지만, 여기서는 순수 interface의 역할만 수행하도록하여 넣지 않음.
이렇게 되면 main 함수에서 다음과 같이 수정해줘야 한다.
int main(void)
{
Monster* monster1 = new MushroomMonster(10); // 수정
Monster* monster2 = new SnailMonster(20); // 수정
monster1->attack();
monster2->attack();
/*
...
*/
Monster* monster3 = new MushroomMonster(10); // 수정
Monster* monster4 = new SnailMonster(20); // 수정
monster1->attack();
monster2->attack();
return 0;
}
new operator로 구상클래스를 인스턴스화 하고 있는 모든 부분에 수정이 가해진다. 의존도가 높아(결합도가 큼)
유지보수가 어려워진다. 생성만 담당하는 간단한 Factory로 결합도를 줄일 수 있다.
class MonsterFactory
{
public:
enum class MonsterType : int
{
eMushroom = 0,
eSnail,
eCount
};
static Monster* createMonster(MonsterType type)
{
switch (type)
{
case MonsterType::eMushroom:
return new MushroomMonster(10);
case MonsterType::eSnail:
return new SnailMonster(20);
default:
// assertion
break;
}
}
};
int main(void)
{
Monster* monster1 = MonsterFactory::createMonster(MonsterFactory::MonsterType::eMushroom);
Monster* monster2 = MonsterFactory::createMonster(MonsterFactory::MonsterType::eSnail);
monster1->attack();
monster2->attack();
/*
...
*/
Monster* monster3 = MonsterFactory::createMonster(MonsterFactory::MonsterType::eMushroom);
Monster* monster4 = MonsterFactory::createMonster(MonsterFactory::MonsterType::eSnail);
monster1->attack();
monster2->attack();
return 0;
}
Factory 클래스는 주로 생성만 담당한다 하지만, 게임쪽에서 Manager란 클래스는 생성&관리 까지하여,
Simple Factory의 기능 + 라이프사이클관리(= 소유권 관리) 까지 포함하는 경우가 더러 있다.