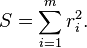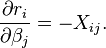Representation
뉴럴 네트워크는 딥러닝의 토대가 되는 기술로 동물의 뇌의 뉴런의 행위를 모방한 알고리즘이다.

위 사진은 뉴런을 도식화 한 것인데 Dendrite는 외부로부터의 전기신호를 받는 "input wires"이고
Axon은 Nuclues에서 가공이 된 신호를 외부로 보내는 "output wire"가 된다. 이는 매우 함수의 형태와 비슷한데

기존의 2진 로지스틱에 빗대어 보면 왼쪽 그림처럼 표현할 수 있겠다.
(타 강의나 프레임워크에서의 표현과 달리 앤드류응교수님의 강의는
'x0 = 1'인 열을 추가해서 'X*∂+b'가 아니라 'X*∂'인 것이
가끔 헷갈리네요 ㅠㅠ 멍청한가 봅니다.)
단일 뉴런의 형태를 위와 같이 표현하면 뉴럴 네트워크란 여러 뉴런이 연결되어있는 것처럼
위의 형태를 다수 연결하여 그룹이 된 것이다.

왼쪽 그림처럼 input으로 x1, x2, x3이 있고 각 뉴런 a1, a2, a3에 넣어주고 있다.
그리고 그 결과를 다시 마지막 뉴런에 보낸다.
이것이 뉴럴 네트워크인 것인다.
(뉴럴 네트워크에서 Layer1은 input layer,
마지막 Layer3은 output layer라 부르며
그 사이의 모든 layer는 hidden layer라고 부른다. 단일 뉴런(로지스틱)에서 처럼
학습셋업시 input의 X벡터와 output의 h(x)의 결과와 y값과의 차이 외에는
보지 않기 때문이다.)
위 뉴럴 네트워크의 hypothesis를 표현하면 이렇게 된다.

여기서 g는 로지스틱 함수이며 bias값을 위한 x0를 포함한 X벡터가 각 Layer2의 뉴런들에 들어가서 그 결과인
a1, a2, a3가 다시 최종 레이어의 input으로 들어가는 형태이다. (물론 bias를 위해 a0가 추가된다.)
이걸 벡터화 해서 표현하면

이렇게 될 것이다.
더 간단히 수식으로 표현하면:
z(j+1)=Θ(j)a(j)
hΘ(x)=a(j+1)=g(z(j+1))
이 된다.
XOR 문제

xor 문제(혹은 xnor)문제는 선형적으로는 풀 수 없다.
xor를 뉴럴네트워크(이하 NN)가 해결할 수 있으면
오른쪽 그래프와 같은 복잡한 문제도 해결 할 수 있을 것이다.
다른 논리 연산들은 대부분 선형적으로(단일 뉴런) 풀 수 있다.
대표적으로 AND를 예로 들면

∂0 = -20, ∂1 = +20, ∂0 = +20이라 가정할때 오른쪽 표와 같은 결과를
얻을 수 있을 것이다.
OR나 NOT등의 논리 연산 또한 선형적으로 구할 수 있으며
결록적으로 XNOR은 이러한 논리연산들을 연결하여 구할 수 있다.
진리표로 예를 들자면

(편의상 c언어의 비트연산자로 표현)
쉽게 알 수 있다. 이처럼 각 논리연산을 하는 뉴런을 연결하면 아래와 같이 될 것이다.

이로 인해 XNOR문제는 NN을 이용해 풀 수 있는 것을 보았다.
마찬가지로 XOR 또한 NOT레이어를 더 추가하든, 최종 결과값을 뒤집든 해서 동일하게 구할 수 있음을 알 수 있다.
'Machine Learning > coursera' 카테고리의 다른 글
| Classification (0) | 2016.02.29 |
|---|---|
| Vectorization (0) | 2016.02.22 |
| Gradient Descent (1) | 2016.02.08 |
| Cost Function - Intuition (2) | 2016.02.08 |
| Linear Regression with one variable - Cost Function (0) | 2016.01.25 |